April 2023, University of Kent, Canterbury
In mid-April, Elaine Hobby and Mel Evans attended the 2023 conference of the European Society for Textual Scholarship (ESTS). The group explores histories and cultures of text (literary and otherwise) and it was a great opportunity to hear about ongoing research from colleagues and also share some updates about the Behn edition (you can read the organising team’s report of the event here). More pertinently, perhaps, the theme of the conference was ‘authorship’, in all its myriad meanings and interpretations, which allowed us to discuss our explorations of and decisions on this topic so far in relation to our new edition of Behn’s works.
Elaine’s paper outlined the principles of the edition and the evolution of the General Editors’ thinking about how to handle the dubia associated with Behn. Should we have a ‘dubia’ volume? Do we include the dubious texts but provide less mark-up and editorial commentary than for a more reliably attested ‘Behn’ text? How do we frame and position those works, many of which have a long-standing association with Behn, that we do not confidently believe are hers (with authorship conventionally defined)?
Elaine’s paper yielded a lively response; the discussions prompted some reflection and thought on the marketability of an edition that did not include a work that people would expect to find on the basis of its long association with an author. Questions, too, were asked about the role of an editorial team to make pronouncements about what an author did or didn’t write to a degree that it would determine a future generation’s appreciation of their literary and wider outputs. Elaine’s view was that the Behn editorial team was approaching this edition from a feminist perspective, and thereby not seeking to dictate the questions and evidence that future researchers might start with. These are the principles we continue to work to.
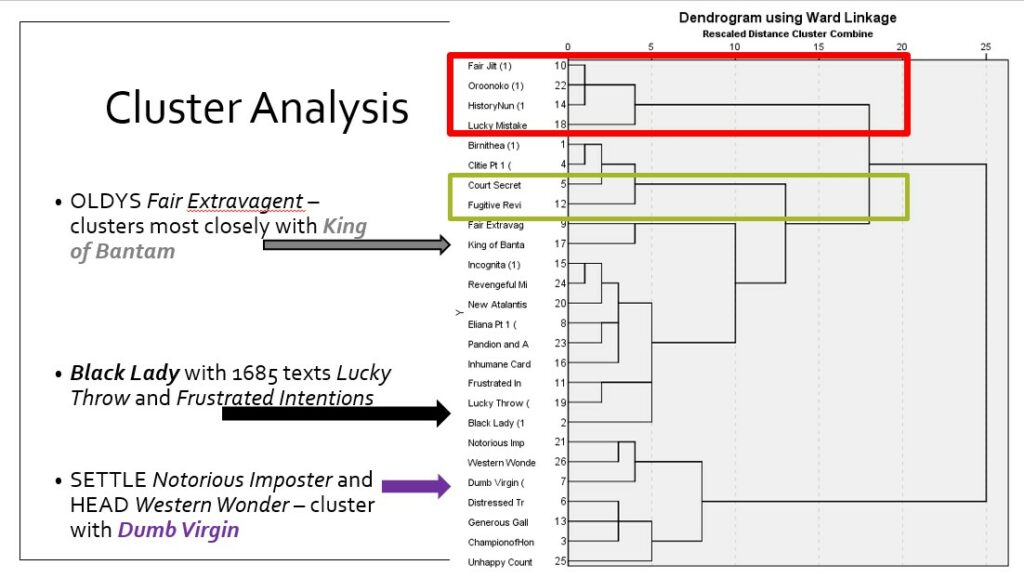
The following day, Mel’s talk explored more specifically the process of computational stylistic analysis, and the steps necessary to establish how such tests might be valid when applied to Behn’s works, such as her prose fiction. The prose has been occupying Mel’s research a fair bit recently, as it’s proven a bit of a Pandora’s box. Part of the challenge relates to the limited availability of Behn’s securely attributed prose works, for which we have four texts: Oroonoko, History of the Nun, The Fair Jilt and – despite its publication shortly after Behn’s death – The Lucky Mistake. Methodologically, the analysis conducted so far suggests that using language from Behn’s other writings is of limited use when examining her prose style from an authorial perspective.
And in terms of answering questions about Behn’s prose style and the likelihood of her authorial involvement in the posthumous short fiction, the results at this stage offer little to suggest that these works are typical of Behn’s prose work – nor, indeed, that the eight texts were written by the same person (Behn, or otherwise). For instance, a basic cluster analysis using 600MFW from a corpus of Restoration prose fiction, including Behn’s known works, successfully groups works by Behn, and also works by another author, Belon, together. However, three of the dubia (The Black Lady, The Court of the King of Bantam and The Dumb Virgin) do not share stylistic traits with Behn using this measure. There is still much to explore here, of course, and the feedback on the talk was very helpful in thinking about other directions to prioritise and pursue.
The trip to Canterbury was a great opportunity to share our thinking and some findings – and provided an ideal trial run in anticipation for next summer’s Aphra Behn Europe conference, which will also take place at the University of Kent: ‘Aphra Behn and her Restoration’, 2-4th July 2024. For more information on that, please visit the University of Kent conference page.



Recent Comments